논문 출처: https://arxiv.org/abs/2405.14458
YOLOv10: Real-Time End-to-End Object Detection
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optim
arxiv.org

Abstract
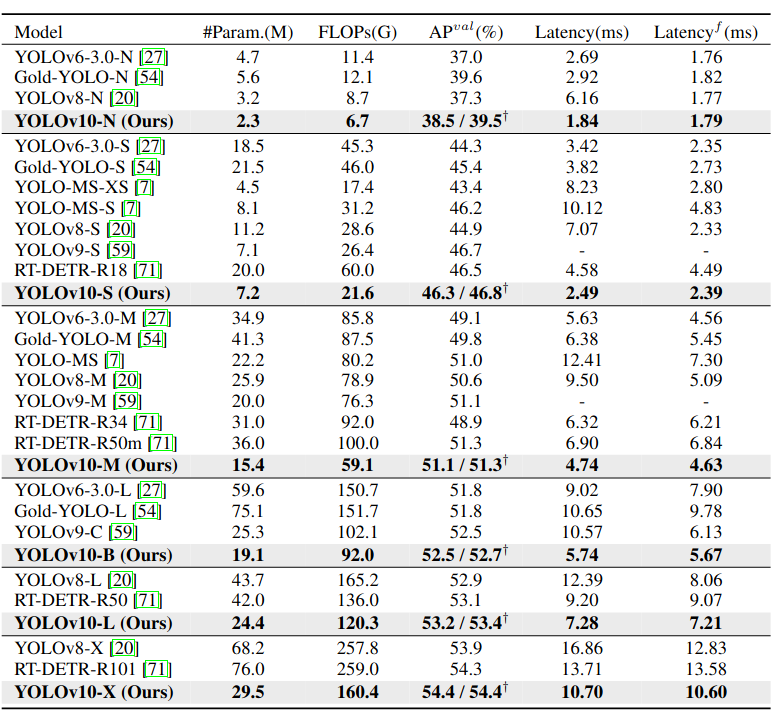
최근 몇 년 동안 YOLO는 real-time object detector분야에서 주도적인 패러다임으로 자리잡았다. 연구자들은 YOLO의 아키텍처 설계, 최적화 목표, 데이터 증강 전략 등 여러 측면을 탐구하여 눈에 띄는 발전을 이뤄냈다. 하지만, YOLO의 후 처리에 대한 NMS(None-Maximum Suppression)에 대한 의존은 YOLO의 종단 간 배포를 방해하고 추론 지연 시간에 부정적인 영향을 미쳤다. 또한 YOLO의 다양한 구성 요소 설계는 포괄적이고 철저한 검토가 부족해 눈에 띄는 계산적 중복을 초래하고 모델의 모델의 능력을 제한한다.YOLOv10에서는 NMS가 없는 YOLO훈련을 위한 일관된 이중 할당 방법을 제시하며, 이는 경쟁력 있는 성능과 낮은 latency를 일궈냈다. YOLOv10-S는 COCO에서 유사한 AP를 유지하면서 RT-DETR-R18보다 1.8배 빠르며, 동시에 2.8배 적은 매개변수와 FLOPs를 자랑한다. YOLOv9-C와 비교했을 때, YOLOv10-B는 동일한 성능을 유지하며 latency는 46% 줄어들고 Parameter도 25%가 적다.
Introduction
Real-time object detection은 이미지에서 객체의 종류와 위치를 신속하게 예측하는 기술로, 자율 주행, 로봇 내비게이션, 객체 추적 등 다양한 분야에서 사용된다. 최근 연구자들은 CNN기반 객체 탐지기를 개발해 실시간 탐지를 목표로 해왔고, YOLO는 성능과 효율성의 균형을 잘 맞춰 많은 인기를 얻었다. 하지만 YOLO는 NMS(None-Maximum Suppression)에 의존하여 추론 속도가 느려지고, 성능이 하이퍼파라미터에 민감해지는 문제를 겪고 있다.
이에 대한 해결책으로, 최근에 DETR 아키텍처를 쓰고나 concentrated on devising CNN-based object detectors등을 시도하고 있지만, 여전히 추가적인 호버헤드가 발생하거나 최적의 성능을 달성하긴 어려웠다. YOLO의 모델 아키텍처 설계 또한 중요한 도전 과제로, 다양한 설계 전략이 제안되었으나 효율성과 정확도 측면에서 포괄적인 검토는 부족했다.
이 연구에서는 YOLO의 정확도와 속도를 개선하기 위해 후처리와 모델 아키텍처 두 가지 측면을 개선했다. NMS 없이도 높은 성능을 유지할 수 있는 이중 레이블 할당 전략을 세지하고, 다양한 구성 요소를 포괄적으로 검토해 효율적이고 정확한 모델 아키텍처를 설계했다. 결과적으로, YOLOv10은 real-time object detection에서 다양한 모델 스케일에 걸쳐 우수한 성능과 효율성을 보여주며 이전 모델들보다 개선된 성능을 제공한다.
Related Work
- Real-time Object Detection:
실시간 객체 탐지는 낮은 latency로 객체를 분류하고 위치를 지정하는 것을 목표로 하며, 이는 실제 응용 분야에서 중요하다. YOLOv1, YOLOv2, YOLOv3은 일반적인 탐지 아키텍처를 구성하며, YOLOv4와 YOLOv5는 CSPNet 설계를 도입하여 DarkNet을 대체하고 데이터 증강 전략, 향상된 PAN, 다양한 모델 스케일을 추가했다. YOLOv6는 BiC와 SimCSPSPPF를 도입하고, YOLOv7은 E-ELAN을 도입해 풍부한 gradient 흐름 경로를 제공하며, 여러 학습 가능한 기법을 연구했다. YOLOv8은 효과적인 특징 추출 및 융합을 위한 C2f 빌딩 블록을 제시하고, Gold-YOLO는 멀티스케일 특징 융합 능력을 향상시키기 위한 GD 메커니즘을 제공했다. YOLOv9은 GELAN을 통해 아키텍처를 개선하고 PGI를 통해 학습 과정을 증강한다. - End-to-end object detectors:
종단 간 객체 탐지는 전통적인 pipeline에서 벗어나 간소화된 아키텍처를 제공한다. DETR은 변환기 아키텍처와 헝가리안 손실을 도입해 1:1 매칭 예측을 수행하며, 수동으로 설계된 구성 요소와 후처리를 제거한다. 이후 다양한 DETR 변형들이 성능과 효율성을 향상시키기 위해 제안되었다. Deformable-DETR은 다중 스케일 변형 가능한 주의 모듈을 활용해 수렴 속도를 가속화하고, DINO는 대비 노이즈 제거, 혼합 쿼리 선택, 두 번의 전방 탐색을 통합했다. RT-DETR은 효율적인 하이브리드 인코더를 설계하고 불확실성 최소 쿼리 선택을 제안해 정확도와 latency를 모두 개선했다. 또 다른 접근 방법으로, 학습 가능한 NMS와 관계 네트워크가 중복 예측을 제거하고, OneNet과 DeFCN이 1:1 매칭 전략을 제안해 Fully convolution network를 사용한 end-to-end object detector를 가능케 했다. FCOSpss는 최적 샘플을 선택하기 위한 positive sample 선택기를 도입했다.
Methodology
- Consistent Dual Assignments for NMS-free Training
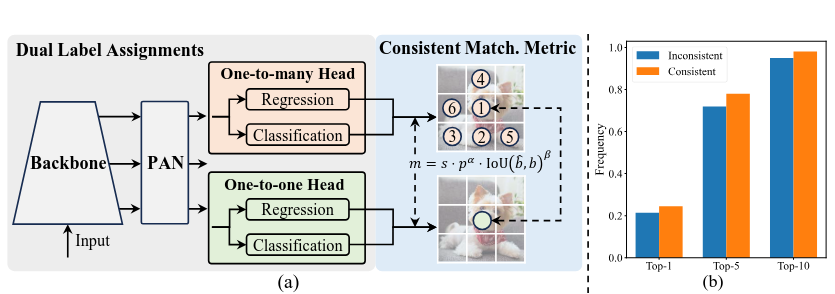
YOLO 모델에서는 객체를 예측하고, 이 예측이 ground truth와 얼만 잘 맞는지 평가하는 방법(matching metric)이 필요하다. 이 방법은 훈련 과정에서 모델이 더 잘 학습 할 수 있도록 해준다. 하지만, 기존의 YOLO 모델은 여러개의 예측을 하나의 객체에 연결(1매칭)해서 학습하는데, 이는 정확도를 높여주지만, 최종 결과를 얻기 위해 불필요한 prediction을 제거하는 과정(NMS)이 필요하다. 이러한 과정이 모델의 latency에 좋지 않은 영향을 준다.
이러한 문제를 해결하기 위해, 불필요한 prediction을 제거한느 과정 없이 모델이 직접 좋은 결과를 내도록 하는 방법 (1:1매칭)을 도입했다. 하지만 이러한 방법은 학습 신호가 약해져서 성능이 떨어질 수 있다. 따라서 두가지 방법의 장점을 결합한 새로운 방식을 채택했다.
- 이중 레이블 할당 (Dual Label Assignments):
- 훈련 중에는 두 가지 매칭 방식을 동시에 사용한다. (one-to-one head, one-to-many head)
- one-to-many: 기존처럼 여러 예측을 하나의 객체에 연결해 강한 학습 신호를 제공한다
- one-to-one: 하나의 예측만 하나의 객체에 연결해 최종 예측이 간단하고 빠르게 이루어지게 한다.
- 일관된 매칭 메트릭 (Consistent Matching Metric):
- 두 가지 방식에서 같은 기준으로 예측을 평가하도록 matching metric을 통일한다.
- 이렇게 하면 두 방식이 서로 잘 맞아 떨어져, 최종 예측이 더 정확해지고 학습이 더 효과적으로 이루어진다.
- 이중 레이블 할당 (Dual Label Assignments):
- Holistic Efficiency-Accuracy Driven Model Design
- 효율성 중심의 모델 설계:
YOLO 모델의 구성 요소 중 일부는 효율성 문제를 일으킨다.- Lightweight classification head: YOLO의 분류와 회귀 헤드는 동일한 구조를 공유하지만, 분류 헤드가 더 많은 계산 비용을 차지한다. 분석 결과, 회귀 헤드가 더 중요한 역할을 하기 때문에, 분류 헤드를 경량화해도 성능 저하가 크지 않다. 그래서, 가벼운 구조를 도입해 분류 헤드를 간소화했다.
- Spatial-channel decoupled downsampling: 기존 YOLO 모델은 공간 크기를 줄이고 채널 수를 늘리는 작업을 동시에 수행해 계산 비용이 높았다. 이 두 작업을 분리해 더 효율적인 다운샘플링 방법을 제안했다. 이를 통해 계산 비용을 줄이고, 성능 저하 없이 효율성을 높였다.
- Rank-guided block design: YOLO는 모든 단계에서 동일한 기본 블록을 사용하는데, 이로 인해 일부 단계에서 불필요한 계산이 발생할 수 있다. 각 단계의 중요도를 분석한 후, 복잡도가 높은 단계를 간소화된 블록으로 대체하여 효율성을 높였다.
- 정확성 중심의 모델 설계:
정확성을 높이기 위해 큰 커널의 컨볼루션과 부분적인 자기 주의를 도입했다.- Large-kernel convolution: 큰 커널의 컨볼루션을 사용하면 모델의 수용 영역이 커져 성능이 향상된다. 그러나 모든 단계에서 큰 커널을 사용하면 오히려 성능이 떨어질 수 있다. 그래서, 깊은 단계에서만 큰 커널을 사용하여 모델 성능을 최적화했다.
- Partial self-attention(PSA): Self-Attention은 모델이 전반적인 정보를 잘 학습할 수 있게 해주지만, 계산 비용이 높다. 이를 해결하기 위해, 일부 채널만 사용해 Self-Attention을 적용했다.
- 효율성 중심의 모델 설계:

Experience
- Implementation Details
YOLOv10은 YOLOv8을 기본 모델로 선택했는데, 이는 뛰어난 속도-정확성 균형과 다양한 모델 크기에서의 가용성 때문이라고 한다. YOLOv10 모델을 개발하는 과정에서, NMS 없이 학습할 수 있는 일관된 듀얼 할당 방식과 효율성-정확성을 동시에 고려한 모델을 설계했다.- 주요 특징:
- YOLOv10은 YOLOv8과 동일하게 N,S,M,L,X와 같은 여러 가지 변형된 모델을 가진다.
- 새로운 변형 모델인 YOLOv10-B도 도입되었으며, 이는 YOLOv10-M의 Width Scale Factor를 단순히 증가시켜 만들었다.
- 검증:
- YOLOv10은 COCO 데이터셋에서 검증되었으며, 이 과정에서 기존과 동일한 처음부터 학습하는 설정을 사용했다.
- 모든 모델의 latency는 T4 GPU에서 TensorRT FP16 환경으로 테스트되었다.
- 주요 특징:
- Model Analyses
- NMS-Free Training with Consistent Dual Assignments:
- YOLOv10-S에서 이 접근법은 end-to-end latency를 4.63ms로 줄이면서, 44.3% AP로 경쟁력 있는 성능을 유지함
- Efficiency Driven Model Design:
- YOLOv10-M의 경우, 이 설계를 통해 11.8M 파라미터와 20.8GFLOPs가 감소했으며, Latency가 0.65ms로 줄었다.
- Accuracy Driven Model Design:
- 이 설계는 YOLOv10-S와 YOLOv10-M의 AP를 각각 1.8과 0.7만큼 눈에 띄게 향상 시켰으며, latency는 각각 0.18ms, 0.17ms만 증가했다. 이는 성능 향상에 따른 latency 증가가 미미함을 나타내며, 우수한 설계임을 입증한다.
- NMS-Free Training with Consistent Dual Assignments:
Conclusion
이 논문에서 YOLO object detection pipeline의 post processing과 모델 아키텍처 두 가지 측면을 모두 개선하는데 초점을 맞췄다.
- Post Processing: NMS(Non-Maximum Suppression, 비최대 억제) 없이 훈련할 수 있는 일관된 듀얼 라벨 할당 방식.
- Model Architecture: 효율성과 정확성을 종합적으로 고려한 모델을 디자인함으로써 성능과 효율성 간의 균형을 개선했다.
source code: https://github.com/THU-MIG/yolov10
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
YOLOv10: Real-Time End-to-End Object Detection. Contribute to THU-MIG/yolov10 development by creating an account on GitHub.
github.com