논문 출처 : https://arxiv.org/abs/2209.02976
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report
arxiv.org
Abstract
빠르게 발전하는 객체 탐지 분야에서 YOLO(You Only Look Once) 시리즈는 오랜 시간 동안 속도와 효율성의 기준을 세워왔다. YOLOv6는 real-time object detection의 한계를 넘어서기 위해 설계된 획기적인 모델이다. EfficientRep 백본, anchor-free 방법, VariFocal Loss 같은 최신 기법들을 도입하여, 더 나은 정확도와 빠른 추론 속도를 달성했고, 이는 학계와 다양한 산업에서 향상된 정확도와 빠른 추론 속도로 사용될 수 있을 것이라 한다.
Introduction
- YOLOv1-3: one-stage detector의 개척자
- YOLOv4: Backbone, Neck, Head로 구성된 탐지 프레임워크의 재구성
- YOLOv5, YOLOX, PPYOLOE, YOLOv7등 여러 모델이 경쟁 중
- YOLOv6가 고려한 점
- Reparameterization(재매개화): RepVGG에서의 재매개화 기법은 탐지에서 아직 충분히 활용되지 않았고, 작은 네트워크에는 단순한 경로 아키텍처가 적합하지만, 큰 모델에서는 파라미터와 계산 비용이 급격히 증가해 실용적이지 않았다.
- Quantization(양자화): 재매개화 기반 Detector의 양자화는 신중하게 처리하지 않으면 학습과 추론 중 성능 저하를 해결하기 어렵기 때문.
- 배포 문제: 이전 작업들은 배포보다는 성능 비교에 집중했고, 실제 환경에서는 Tesla T4와 같은 저전력 GPU가 비용 효율적이고 좋은 추론 성능을 제공했다.
- 고급 도메인 전략: 레이블 할당과 손실 함수 설계 같은 전략은 구조적 변동을 고려해 추가 검증이 필요하다.
- 학습 전략 조정: 배포를 위해 정확도를 높이면서 추론 비용을 늘리지 않는 학습 전략 조정이 필요하다. (Knowledge Distillation 등)
- YOLOv6의 특징
- 다양한 네트워크 아키텍처: 다양한 크기의 네트워크를 산업 응용에 맞게 재구성했고, 작은 모델은 단순한 단일 경로 backbone을 사용하고 큰 모델은 효율적인 다중 분기 block을 사용한다.
- 자기 증류 전략(Self-Distillation Strategy): Classification과 Regression 작업 모두에서 자기 증류를 적용하고, 지식 조정을 통해 모델 학습을 더욱 효율적으로 만든다.
- 최신 탐지 기법 검증: 레이블 할당, 손실 함수, 데이터 증강 기법을 광범위하게 검증하고 선택적으로 채택하여 성능을 향상시킴.
- 개선된 양자화: RepOptimizer와 채널별 증류를 활용하여, 43.3% COCO AP와 869 FPS의 추론 성능을 달성함
Method
- 네트워크 디자인:
- Backbone: YOLOv6는 작은 네트워크에서 RepVGG 백본을 사용하여 더 강력한 특징 표현력을 제공하며, 대형 모델에는 RepBlock과 CSPStackRep 블록을 결합하여 효율성을 높였다. RepBlock은 작은 네트워크에서 좋은 성능을 발휘하며, 대형 모델에서는 CSPStackRep 블록을 사용해 파라미터와 계산 비용을 줄였다.
- Neck: PAN(Path Aggregation Network) 토폴로지를 채택하여 YOLOv4와 YOLOv5의 접근 방식을 개선함. RepBlocks 또는 CSPStackRep Blocks를 사용해 Rep-PAN으로 향상시킴.
- Head: Decoupled Head를 간소화하여 더 효율적인 Efficient Decoupled Head로 개선함.
- 레이블 할당:
- TAL(Task Alignment Learning)이 더 효과적이며 학습 친화적인 것을 발견
- 손실 함수:
- Classification Loss: VariFocal Loss
- Regression Loss: SIoU(Scaled Intersection over Union) 및 GIoU(Generalized Intersection over Union) 손실
- 산업 적용 개선:
- 자기 증류(self-distillation)와 추가 학습 epoch를 포함한 공통 실습과 트릭을 도입했다. 자기 증류는 Classification과 박스 Rergression을 각각 teacher 모델로 감독하며, DFL(Deep Feature Learning)을 통해 Box Regression의 증류를 가능하게 한다. Soft와 Hard Label의 정보 비율을 동적으로 감소시켜 Student 모델이 학습 과정에서 지식을 효율적으로 습득하도록 한다. 또한, 평가 시 추가적인 회색 경계 없이 성능을 유지하기 위한 해결책을 제공함.
- 양자화 및 배포:
- RepOptimizer를 사용하여 양자화 친화적인 가중치를 얻고, QAT(Quantization Aware Training)와 채널별 증류(channel-wise distillation), 그래프 최적화를 적용하여 극한의 성능을 추구했다. 양자화된 YOLOv6-S는 42.3% AP와 869 FPS(배치 크기 32)의 성능을 달성하여 새로운 최첨단 기록을 세웠다.
Backbone
이전 연구들에 따르면, 다중 분기 네트워크는 종종 단일 경로 네트워크보다 더 나은 분류 성능을 달성할 수 있지만, 병렬성의 감소와 latency의 증가를 초래하는 경우가 많다. 반면, VGG와 같은 단일 경로 네트워크는 높은 병렬성과 적은 메모리 사용량 덕분에 더 높은 추론 효율성을 제공한다.
RepVGG에서 제안된 구조적 재매개화 방법은 훈련 시의 다중 분기 구조를 추론 시의 단일 경로 아키텍처로 분리하여 속도와 정확성 간의 균형을 개선했다. 이러한 연구에 영감을 받아, YOLOv6는 EfficientRep이라는 효율적인 재매개화 가능한 Backbone을 설계했다.
- 작은 모델 : 훈련 단계에서 백본의 주요 구성 요소는 RepBlock이다. 각 RepBlock은 추론 단계에서 3x3의 합성곱 층(RepConv)로 변환된다. 3x3 합성곱은 main GPU와 CPU에 최적화되어 있으며, 높은 계산 밀도를 제공하여 하드웨어의 계산능력을 충분히 활용하게 해준다. 이로 인해 Latency가 크게 줄어들고 표현 능력또한 향상되는 효과를 가져온다.
- 중간 및 대형 모델 : 모델 용량이 확장되면서, 단일 경로 네트워크의 계산 비용과 파라미터 수가 기하급수적으로 증가한다. 따라서 CSPStackRep Block을 수정해 중간 및 대형 네트워크의 Backbone을 구축했다. CSPStackRep Block은 세 개의 1x1 합성곱 층과 두 개의 RepVGG Block 또는 RepConv으로 구성된 SubBlock의 Stack, 잔차 연결로 구성된다. 또한, 계산 비용을 과도하게 증가시키지 않으면서 성능을 향상시키기 위해 CSP(Cross Stage Partial)가 채택되었다. CSPRepResStage와 비교해 더 간결한 구조를 가지고 있으며, 정확성과 속도 간의 균형을 고려했다.

Neck
Object Detection에서 다양항 스케일에서의 특징 통합이 매우 중요하고, 효과적인 부분으로 입증되었다. YOLOv6는 YOLOv4와 5에서 사용된 수정된 PAN(Path Aggregation Network) 포톨로지를 Detection Neck의 기본으로 채택했다.
- Neck: YOLOv6에서는 YOLOv5에서 사용된 CSP-Block을 RepBlock(작은 모델의 경우) 또는 CSPStackRep Block(큰 모델의 경우)으로 대체하고, 이에 따라 Neck의 Width와 Height을 조정했다. 이러한 조정을 통해 YOLOv6의 넥은 Rep-PAN으로 불린다.
Head
- Efficient Decoupled Head: YOLOv5의 탐지 헤드는 Classification과 Localization branch가 파라미터를 공유하는 couple head구조를 가지고 있다. 반면, FCOS와 YOLOX는 두 branch를 decoupling하고 각 브랜치에 추가적인 3x3 합성곱 층을 도입하여 성능을 향상시킨다. YOLOv6에서는 혼합 채널 strategy를 채택해 더욱 효율적인 decoupled head를 설계했다. 중간 3x3 합성곱 층의 개수를 하나로 줄였고, 헤드의 너비는 backbone과 neck의 너비 배율에 따라 조정된다. 이러한 수정은 계산 비용을 줄여 Latency를 낮추는데 기여했다.
- Anchor-Free: anchor가 없는 detector는 일반화 능력과 decoding 예측 결과의 단순성 덕분에 주목받고 있는 추세이다. Post Processing에 필요한 시간이 크게 줄었다. Anchor-free detector는 두가지 방식이 존재하는데, 하나는 anchor point based이고 다른 하나는 keypoint based이다. YOLOv6에서는 앵커 포인트 기반 패러다임을 채택했고, 이 방식에서 box regression branch가 실제로 anchor point에서 bbox의 네 면까지의 거리를 예측한다.
Loss Functions
Object Detection은 두 가지 하위 작업, 즉 Classification과 Localization을 포함한다. 이 두 작업에는 각각의 손실 함수가 필요한데, Classification Loss 함수와 Box Regression Loss 함수이다. 각 하위 작업에 대해 다양한 손실 함수가 제안되었다.
- Classification Loss Function:
- Cross-Entropy Loss: 가장 기본적이고 널리 사용되는 classification loss 함수로, 분류의 확률을 최대화하는 방향으로 작동함.
- Focal Loss: 클레스의 불균형 문제를 해결하기 위해 설계된 손실 함수로, 어려운 예제에 더 많은 가중치를 부여함.
- VariFocal Loss: Focal Loss의 변형된 버전으로, 다양한 예제의 중요도를 조절하여 더 세밀한 학습이 가능하도록 한다.
- Box Regression Loss Function:
- IoU(Intersection over Union) Loss: IoU를 기반으로 한 손실 함수로, 예측 박스와 실제 박스 간의 겹치는 정도를 측정.
- GIoU(Generalized IoU) Loss: IoU의 일반화된 형태로, 예측 박스와 실제 박스의 겹침 외에도 두 박스 사이의 거리를 고려함.
- SIoU(Scaled IoU) Loss: IoU의 Scale버전으로, 박스 크기와 위치에 따라 손실 값을 조정함.
- Object Loss:
- Object Loss는 FCOS에서 처음 제안된 개념으로, 낮은 품질의 BBox Score를 감소시켜 Post Processing단계에서 필터링 할 수 있도록 한다. YOLOX에서도 사용되어 네트워크의 수렴 속도를 가속화하고 정확도를 향상시키는데 기여했다. YOLOv6에서 FCOS와 YOLOX와 같은 Anchor-Free 프레임워크로서 객체 손실을 도입해보았지만, 좋은 효과를 주진 못했다.
Quantization and Deployment
산업 배포를 위해, 런타임 속도를 더욱 향상 시키면서 성능 손실을 최소화하기 위해 양자화를 채택하는 것이 일반적인 방법이다. 양자화 모델의 계산 효율성을 높이기 위해 사용한느 기법으로, 두가지가 있는데,
- 사후 양자화 (Post-Training Quantization, PTQ): 모델을 학습 후에 양자화 하는 방법. 소규모의 calibration dataset만으로 직접 모델을 양자화한다. 학습 데이터에 접근할 필요가 없어 비교적 간단하게 구현 가능
- 양자화 인식 학습 (Quantization-Aware Training, QAT): 학습 과정 중에 양자화를 인식하여 성능을 더욱 향상시키는 방법. QAT는 일반적으로 Knowledge Distillation과 함께 사용되어, 양자화의 영향을 고려하며 학습이 진행된다.
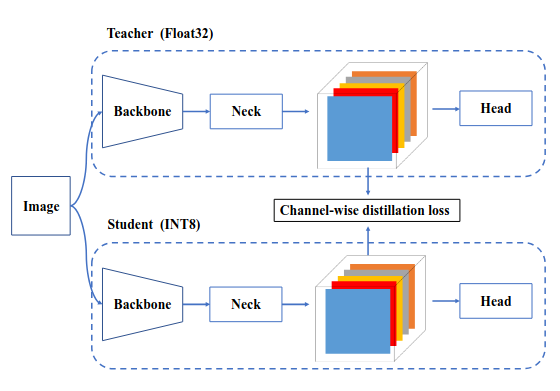
하지만 YOLOv6는 많은 양의 재매개화 블록을 사용하고 있어, 기존의 PTQ 기술로는 높은 성능을 달성하기 어렵고, 학습과 추론 시에 가짜 양자화기(Faux Quantizer)를 맞추는것이 어려워 QAT를 적용하는데 한계가 있다. 이를 해결하기 위해 RepOptimizer와 채널별 증류 (Channel-Wise-Distillation)를 활용한 양자화 접근 방식을 적용했다. RepOptimizer는 모델의 파라미터를 양자화에 맞게 조정해 PTQ 친화적인 가중치를 생성하며, 채널별 증류는 학습 과정에서 양자화의 영향을 최소화한다. 또한, 그래프 최적화를 통해 추론 성능을 극대화한다.
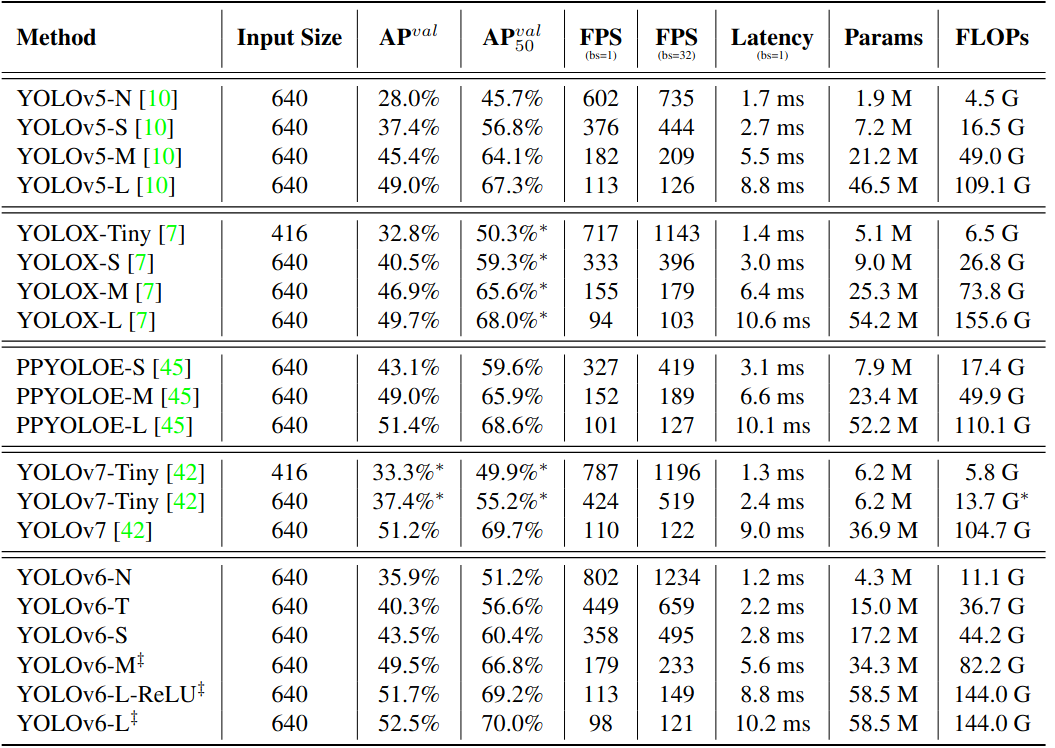
Backbone Network Performance
code source: https://github.com/meituan/YOLOv6
GitHub - meituan/YOLOv6: YOLOv6: a single-stage object detection framework dedicated to industrial applications.
YOLOv6: a single-stage object detection framework dedicated to industrial applications. - meituan/YOLOv6
github.com
'논문' 카테고리의 다른 글
| [논문] YOLOv10: Real-Time End-to-End Object Detection 리뷰 (0) | 2024.08.21 |
|---|---|
| [논문] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors 리뷰 (0) | 2024.08.21 |
| [논문] YOLOv4: Optimal Speed and Accuracy of Object Detection (0) | 2024.08.19 |
| [논문] YOLOv3: An Incremental Improvement 리뷰 (1) | 2024.08.18 |
| [논문] YOLOv2 리뷰 (0) | 2024.08.18 |