논문 출처 : https://arxiv.org/abs/1804.02767
YOLOv3: An Incremental Improvement
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3
arxiv.org
YOLOv3(You Only Look Once version 3)는 Joseph Redmon과 Ali Farhadi가 2018년에 발표한 물체 인식 모델로, YOLOv2의 단점을 보완하고 성능을 더욱 향상시킨 버전이다. 다양한 크기의 물체를 효과적으로 인식할 수 있도록 여러 가지 기술적 개선이 도입되었으며, 특히 빠른 속도와 높은 정확도의 균형을 유지하면서도, 깊은 네트워크 구조와 멀티스케일 예측을 통해 성능을 크게 향상시켰다.
Backbone: Darknet-53
YOLOv3는 새로운 백본 네트워크로 Darknet-53을 사용했는데, 이는 53개의 conv layers로 구성된 깊은 네트워크로, ResNet에서 사용된 잔차 블록(Residual Blocks)을 채택해 더 깊은 네트워크를 안정적으로 학습할 수 있게 한다.
- 특징:
- 이전 버전의 Darknet-19보다 깊은 네트워크로, 더욱 복잡한 특징을 추출할 수 있다.
- ResNet의 아이디어를 차용해, 기울기 소실 문제를 해결하고 더 깊은 구조에서도 효과적인 학습이 가능하다.
- FLOPs(Floating Point Operations) 대비 효율적인 연산을 통해, 이미지넷 분류 작업에서 기존 모델들에 비해 경쟁력 있는 성능을 보여줍니다.

Multi-Scale Predictions
YOLOv3는 멀티스케일 예측을 도입하여, 서로 다른 크기의 물체를 인식할 수 있는 능력을 크게 향상시켰다. 이를 위해 YOLOv3는 Feature Pyramid Network (FPN) 구조를 활용하여 3개의 다른 스케일에서 예측을 수행한다.
- 작동 방식:
- 네트워크의 다른 레이어에서 나오는 특징 맵을 사용해, 작은, 중간, 큰 크기의 물체를 각각 인식할 수 있다.
- 각 스케일에서 3개의 앵커 박스를 사용하여 바운딩 박스를 예측하며, 총 9개의 앵커 박스가 사용된다.
- 다양한 스케일에서 예측함으로써, 작은 물체와 큰 물체를 모두 잘 인식할 수 있다.
- Feature Map : 13 x 13, 26 x 26, 52 x 52를 사용
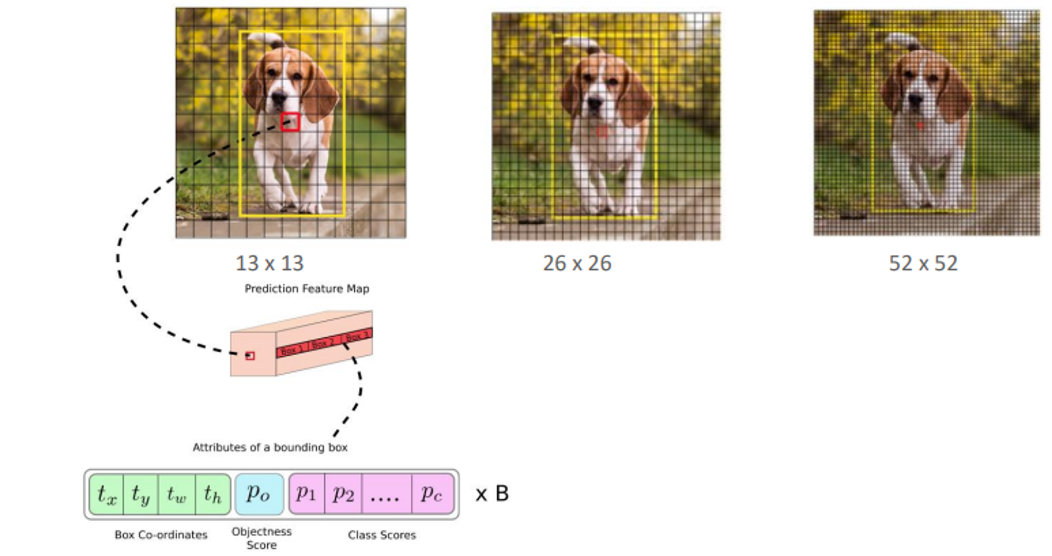
Bounding Box Predictions
바운딩 박스의 좌표를 예측하는 방식에서 개선이 이루어졌다.
- 선형 활성화 함수: YOLOv3는 바운딩 박스의 중심 좌표와 크기를 예측할 때, 선형 활성화 함수를 사용하여 더 정확한 좌표 예측을 가능하게 했다.
- 기존 모델과의 차이점: YOLOv3는 이전 버전에서 사용된 비선형 활성화 함수 대신, 선형 활성화 함수를 사용함으로써 예측의 직관성과 정확도를 높였다.
Class Prediction
로지스틱 회귀를 사용하여 각 바운딩 박스에서 물체의 클래스를 예측한다.
- 다중 라벨 예측: YOLOv3는 소프트맥스 함수 대신 로지스틱 회귀를 사용하여, 각 클래스에 대한 독립적인 확률을 계산하며 이를 통해 한 바운딩 박스에서 여러 개의 클레스가 동시에 예측 될 수 있다. 이렇게 되면 다중 라벨 분류 문제에 적합해지며, 단일 물체가 여러 클레스에 속하는 경우에도 효과적으로 대응 할 수 있게된다.
Conclusion
YOLOv3는 물체 인식에서 속도와 정확도를 동시에 유지하면서도 더 복잡한 장면과 다양한 크기의 물체를 효과적으로 인식할 수 있는 강력한 모델이다. 다만, 일부 작은 물체 인식의 한계와 모델 크기의 부담이 있지만, 전체적으로 보면 YOLOv3는 물체 인식 분야에서 중요한 진전을 이룬 모델이다.
code source : https://github.com/ultralytics/yolov3
GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
YOLOv3 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov3 development by creating an account on GitHub.
github.com
'논문' 카테고리의 다른 글
| [논문] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors 리뷰 (0) | 2024.08.21 |
|---|---|
| [논문] YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications 리뷰 (0) | 2024.08.19 |
| [논문] YOLOv4: Optimal Speed and Accuracy of Object Detection (0) | 2024.08.19 |
| [논문] YOLOv2 리뷰 (0) | 2024.08.18 |
| [논문] YOLO (You Only Look Once) 리뷰 (0) | 2024.08.18 |