논문 출처 : https://arxiv.org/abs/2004.10934
YOLOv4: Optimal Speed and Accuracy of Object Detection
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large datasets, and theoretical justification of the result, is required. Some features operate
arxiv.org
Introduction
CNN 기반 객체 감지기는 주로 추천 시스템에 사용되며, 정확한 모델은 느리지만 부정확한 모델은 빠릅니다. 실시간 객체 감지기의 정확도를 향상시키면 독립적인 프로세스 관리에 활용될 수 있다. 최신 신경망은 실시간 작동이 어렵고 많은 GPU를 필요로하지만, YOLOv4에서는 일반적인 GPU에서 실시간으로 작동하고 훈련 가능한 CNN을 개발하려고 했다.

이 연구의 주요 목표는 이론적인 계산량 지표(BFLOP)보다 생산 시스템에서 객체 감지기의 빠른 작동 속도와 병렬 계산에 대한 최적화에 중점을 두는 것이다. GPU를 사용해 실시간으로 고품질의 객체 감지 결과를 얻을 수 있도록 설계된 모델을 누구나 쉽게 학습 할 수 있게 하는게 목표라고한다.
- 1080 Ti 또는 2080 Ti GPU를 사용해 초고속 및 고정확도의 객체 감지기를 훈련할 수 있는 효율적이고 강력한 모델을 개발했다.
- 객체 감지기 훈련 시 최신 Bag-of-Freebies와 Bag-of-Specials 방법의 영향을 검증했다.
- 최신 방법들을 수정하여 단일 GPU 훈련에 더 효율적이고 적합하게 만들었다. (예: CBN, PAN, SAM 등)
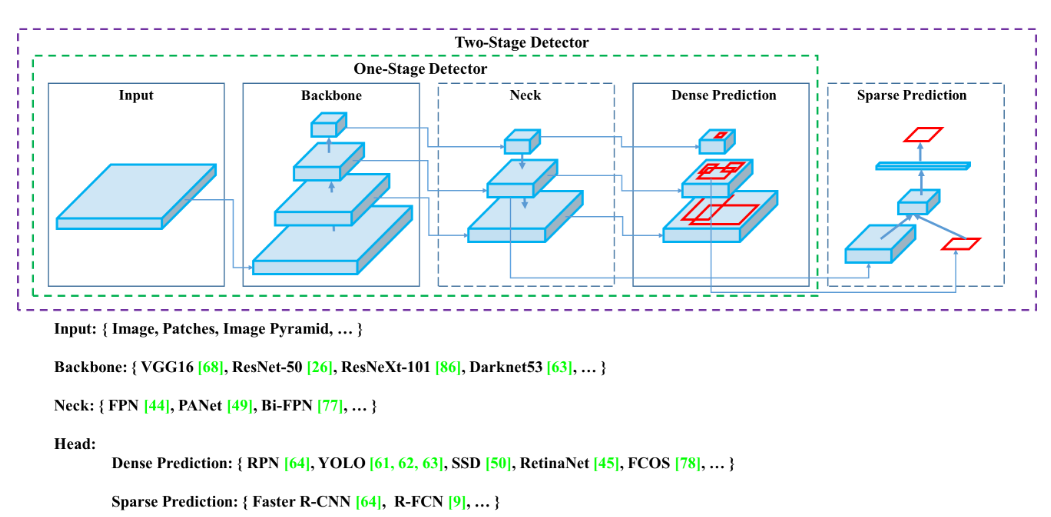
Object Detection Models
- Modern Object Detector : Backbone + Head의 두 부분으로 구성되어있다. 백본은 이미지넷(ImageNet)에서 사전 학습된 네트워크로, GPU에서는 VGG, Resnet, DenseNet과 같은 모델이, CPU에서는 MobileNet, ShuffleNet등이 사용된다. 헤드는 클레스와 바운딩 박스를 예측하는데,
- One-Stage Detector : YOLO, SSD, RetinaNet등이 대표적이며, CornerNet, FCOS와 같은 Anchor-free 모델들이 개발되었다.
- Two-Stage Detector : R-CNN 시리즈가 대표적이며, RepPoint와 같은 Anchor-free 모델도 존재한다.
- 이 외에도 Backbone과 Head사이에 Neck을 추가해 다양한 Feature Map을 collect하는 구조도 존재하며, FPN, PAN, BiFPN등이 이에 해당한다. 이를 통해서 Object Detection의 성능을 더욱 향상 시킬 수 있다.
Bag of freebies
Object Detection의 추론 비용을 늘리지 않으며, train strategy를 개선해 성능을 높이는 다양한 방법들이 있다. 주로, 데이터 증강 (Data Augmentation), 라벨 스무딩 (Label Smoothing), 손실 함수 개선 (Loss Function Enhancement)을 통해서 object detection 모델의 정확도와 robust를 크게 향상 시킬 수 있다.
- 데이터 증강 (Data Augmentation): 데이터 증강은 훈련 데이터의 다양성을 증가시켜 모델이 다양한 환경에서 높은 성능을 발휘할 수 있게 돕는다. 대표적인 방법으로 밝기, 대비, 채도 조절등과 같은 photometric distortions과 회전, 크기 조정, flip과 같은 geometric distortions이 있다. 추가로, Random erase, CutOut, MixUp, CutMix등과 같은 기법들도 객체 탐지 성능을 높이는데 사용된다.
- 라벨 스무딩 (Label Smoothing): Object Detection에서 클레스 간 불균형이 발생할 수 있는데, 라벨스무딩을 통해 이러한 문제를 해결할 수 있다. 라벨 스무딩은 hard level을 soft level로 변환해 모델이 더욱 견고하게 학습 될 수 있게 한다. 이와 함께 Knowledge Distillation 기법을 활용해 더 나은 라벨을 생성하는 방법도 있다.
- 손실 함수 개선 (Loss Function Enhancement): 기존의 손실 함수는 Bounding Box regression에서 좌표를 독립적으로 취급해 객체의 완전성을 고려하지 못했다. 이를 해결하기 위해 IOU(Intersection over Union) 손실이 제안되었고, 그 이후에 IOU보다 개선된 GIoU, DIoU,CIoU 손실 함수가 개발되었다. 이들 함수는 객체의 크기, 중심 거리, 종횡비 등을 고려해 더욱 정확한 BBox를 예측할 수 있게 해주었다.
Methodology
YOLOv4의 기본 목표는 이론적인 계산 지표(BFLOP)보다는 실제 생산 시스템에서의 신경망 운영 속도와 병렬 연산 최적화에 중점을 두었다.
- For GPU: CSPResNeXt50 및 CSPDarknet53 모델은 소수의 그룹(1~8)을 사용하는 컨볼루션 레이어를 활용해 최적화했다.
- For VPU: EfficientNet-lite, MixNet, GhostNet, MobileNetV3 모델은 그룹화된 컨볼루션 레이어를 사용하되, SE 블록을 배제하여 최적화되었다.
Selection of architecture
아키텍쳐 선택 과정에서는 input 네트워크 해상도, convolution layer의 수, parameter의 수, output layer(filter)사이의 균형을 찾는 것이 중요하다.
- Selection of Backbone: CSPResNeXt50은 ImageNet 데이터셋에서 Object Classification 성능이 우수한 반면, CSPDarknet53은 MS COCO 데이터셋에서 Object Detection 성능이 더 뛰어나다.
- Additional Module: 수용 영역을 확장하고 파라미터 집계를 최적화하기 위해 CSPDarknet53 위에 SPP 블록을 추가하여 속도 저하 없이 수용 영역을 크게 확장한다. 또한, YOLOv3에서 사용된 FPN 대신 PANet을 사용하여 백본의 다른 레벨에서 파라미터를 집계한다.

따라서 YOLOv4의 모델 아키텍쳐는 아래와 같이 구성되었다.
- Backbone : CSPDarkNet53
- Additional Module : SPP
- Neck : PANet 경로 집계
- Head : YOLOv3 (Anchor-Based)
Selection of BoF and BoS
Object Detection 학습을 개선하기 위해 CNN에서 사용하는 다양한 기법들에 대해 설명해준다.
- 활성화 함수 (Activation):
- ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, Mish등 다양한 활성화 함수가 사용된다.
- selection에서 PReLU와 SELU는 훈련이 더 어려워 제외되었고, ReLU6는 양자화 네트워크에 특화되어 있어 제외되었다.
- BBox Regression Loss:
- MSE,IoUm GIoU,CIoU,DIoU등 다양한 손실 함수가 사용된다
- 데이터 증강 (Data Augmentation):
- CutOut, MixUp, CutMix 등 여러 데이터 증강 기법이 적용된다.
- Regularization Method:
- DropOut, DropPath, Spatial DropOut, DropBlock 등 정규화 기법이 사용된다.
- DropBlock은 다른 정규화 기법들과 비교해 우수한 성능을 보여 선택되었다.
- Normalization of Network Activations:
- Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN) 등의 정규화 기법이 존재한다.
- 단일 GPU를 사용하는 train strategy에 중점을 두어, SyncBN은 고려하지 않았다고 한다.
- Skip-connections:
- Residual connections, Weighted residual connections, Multi-input weighted residual connections, Cross stage partial connections (CSP) 등 다양한 스킵 연결 방식이 있다.
YOLOv4 상세 설명
1. Backbone: 강력한 특징 추출을 위해 CSPDarknet53을 사용했다.
2. Neck:
- SPP (Spatial Pyramid Pooling): 다양한 크기의 수용 영역을 활용하여 특징을 추출.
- PAN (Path Aggregation Network): 여러 백본 레벨에서 파라미터를 집계하여 성능을 향상시킴.
3. Head (헤드):
- YOLOv3: 객체 탐지 결과를 예측하는 데 사용됨.
4. BoS & BoF
- Bag of Freebies (BoF) for Backbone (백본용 자유 기법):
- 데이터 증강: CutMix와 Mosaic 기법을 사용하여 훈련 데이터의 다양성을 증가.
- 정규화: DropBlock 정규화 기법을 적용하여 모델의 일반화 성능을 개선.
- 클래스 라벨 스무딩 (Class Label Smoothing): 클래스를 부드럽게 표현하여 과적합을 방지.
- Bag of Specials (BoS) for Backbone (백본용 특별 기법):
- 활성화 함수: Mish 활성화 함수를 사용하여 비선형 변환을 향상시킴.
- Cross-stage Partial Connections (CSP): 네트워크의 깊이를 증가시키지 않고 특징을 효율적으로 집계함.
- Multi-input Weighted Residual Connections (MiWRC): 다양한 입력으로부터 가중치를 조정하여 더 효과적인 특징 학습을 가능하게 함.
- Bag of Freebies (BoF) for Detector (탐지기용 자유 기법):
- 손실 함수: CIoU-loss를 사용하여 더 정밀한 Bbox regression을 수행한다.
- 정규화: CmBN (Cross-mini-batch Normalization)과 DropBlock을 사용함.
- 데이터 증강: Mosaic 기법을 포함하여 데이터의 다양성을 높였다.
- 자기-적대적 훈련 (Self-Adversarial Training): 모델의 강건성을 향상시킨다.
- 그리드 민감도 제거: 모델의 그리드 기반 민감도를 줄인다.
- 여러 앵커: 단일 ground truth에 대해 여러 Anchor를 사용하여 Detection 성능을 개선한다.
- 코사인 주기적 스케줄러: Cosine annealing scheduler를 사용하여 학습률을 조절한다.
- 최적의 하이퍼파라미터: 모델 성능을 극대화하기 위해 하이퍼파라미터를 최적화한다.
- 무작위 훈련 크기: 다양한 크기의 입력을 사용하여 모델의 일반화 능력을 향상시킨다.
- Bag of Specials (BoS) for Detector (탐지기용 특별 기법):
- 활성화 함수: Mish 활성화 함수를 사용한다.
- SPP 블록: SPP (Spatial Pyramid Pooling) 블록을 추가하여 수용 영역을 확장한다.
- SAM 블록: SAM (Selective Attention Module) 블록을 사용하여 중요한 특징을 강조함.
- PAN 경로 집계 블록: **PANet (Path Aggregation Network)**을 사용하여 백본 레벨에서 파라미터를 집계한다.
- DIoU-NMS: DIoU (Distance-IoU) Non-Maximum Suppression(NMS)을 사용하여 박스 정합을 개선함.
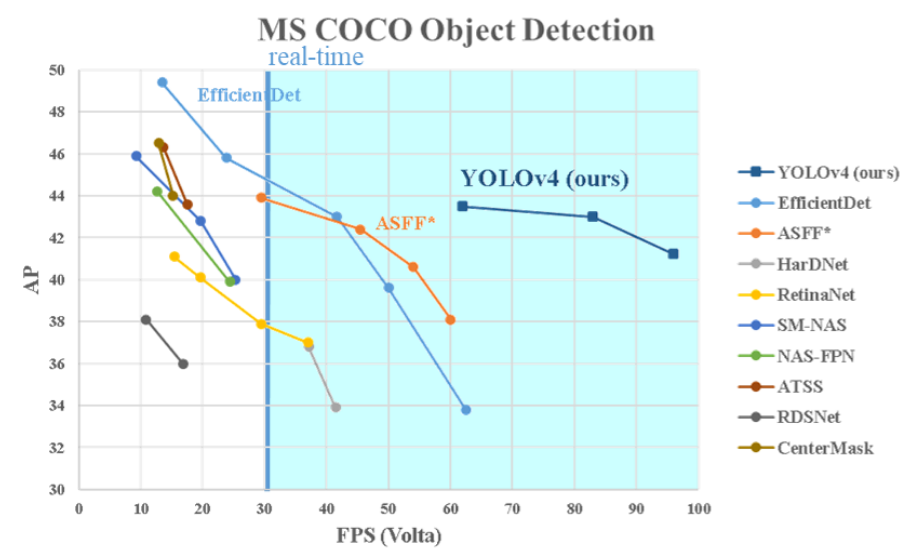
Conclusion
YOLOv4는 표에서 보여진 모든 alternative object detector들보다 속도와 정확도에서 우수한 성능을 자랑한다. 8-16GB VRAM을 가진 일반 GPU에서 훈련과 사용이 가능하여, 널리 활용될 수 있는 실용적인 솔루션을 제공한다. YOLOv4의 성과는 하나의 단계(anchor-based) detection 개념의 유효성을 입증하며, 다양한 기능을 검증하고 최적화하여 높은 정확도와 빠른 처리 속도를 동시에 달성했다.
source code: https://docs.ultralytics.com/models/yolov4/
'논문' 카테고리의 다른 글
| [논문] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors 리뷰 (0) | 2024.08.21 |
|---|---|
| [논문] YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications 리뷰 (0) | 2024.08.19 |
| [논문] YOLOv3: An Incremental Improvement 리뷰 (1) | 2024.08.18 |
| [논문] YOLOv2 리뷰 (0) | 2024.08.18 |
| [논문] YOLO (You Only Look Once) 리뷰 (0) | 2024.08.18 |